InfoFormulizer - Projektbericht
Projektpartner
Kurzvorstellung und Ausgangssituation
In der Service-Industrie ist es nach wie vor eine große Herausforderung schnell und effektiv auf Probleme zu reagieren. Diese werden meist informell und symptomatisch von Kundinnen und Kunden in Form von Supportanfragen vorgebracht. Diese Supportanfragen liegen meist in schriftlicher Form (z. B. Eintrag in Ticketsystem, E-Mail, Chatverlauf) oder als Transkription einer telefonischen Anfrage vor. Charakteristisch für derartige Supportanfragen sind ungenaue, unvollständige und widersprüchliche Angaben, was die Bearbeitung und in diesem Zuge auch Lösungsfindung erheblich erschwert.
Den Mitarbeiterinnen und Mitarbeitern der Service-Industrien stehen zur Bearbeitung der Supportanfragen (d.h. Lösungsfindung) meist eine Vielzahl von textbasierten Informationsquellen zur Verfügung. Hierbei handelt es sich beispielsweise um FAQs, Handbücher, technische Dokumentationen oder sonstige Dokumente. Das manuelle Durchsuchen dieser (großen) Datenmenge ist eine sehr zeitaufwendige und fehleranfällige Aufgabe. Meist müssen mehrere Absätze gelesen werden und deren Relevanz für die Lösungsfindung beurteilt werden und eine erhebliche Anzahl an Dokumenten durchgesehen werden. Häufig werden hierbei jedoch relevante Absätze übersehen oder aus Zeitgründen bei der ersten annähernd passenden Textpassage die weitere Suche eingestellt, wodurch weitere möglicherweise relevanten Absätze oder Datenquellen gar nicht mehr in die Lösungsfindung einbezogen werden. Neben dem immensen Wettbewerbsdruck, der eine möglichst kosteneffektive Beantwortung von Supportanfragen erforderlich macht, unterliegen zahlreiche Supportanfragen strikten Zeitlimits, die eine Beantwortung innerhalb einer bestimmten Zeitspanne erforderlich machen (z. B. da der Kunde / die Kundin einen bestimmten Supportvertrag hat, der ihr eine maximale Antwortdauer garantiert, oder weil es sich um sicherheitskritische Probleme handelt, die eine unmittelbare Lösung erfordern).
Um diese Herausforderungen anzugehen, wurde in diesem Projekt ein KI-basierter Ansatz entwickelt, um Mitarbeiterinnen und Mitarbeiter bei der Lösungsfindung zu unterstützen. Basierend auf einer gegebenen Supportanfrage identifiziert der Ansatz die für die Problemlösung relevanten Abschnitte in den Dokumenten, welche im Falle einfacher Anfragen direkt als Antwort genutzt werden können. In Kooperation mit den Anwendungspartnern, wurde hierfür ein eigener, unüberwachter Ansatz mit minimalen Anforderungen entwickelt und als prototypisches Framework implementiert. Das Framework erlaubt eine flexible Anpassung an die Bedürfnisse des jeweiligen Unternehmens, sowie Skalierbarkeit hinsichtlich der Anzahl an Dokumenten und des Supportanfragendurchsatzes. Hierdurch garantiert der „InfoFormulizer“ eine breite Anwendbarkeit für Unternehmen mit unterschiedlichen Profilen und Größen.
- Verwendete TechnologienHide
-
Visualisierung der relevantesten Worte in einer Textsammlung, die mit dem LDA-Verfahren modelliert wurde.
Die Latent Dirichlet Allocation (LDA) ist der de facto Industriestandard im Bereich des unüberwachten Lernens von sogenannten Topics aus natürlichsprachlichen Texten. Hiermit können aus einem Text Themen, welche dieser behandelt, extrahiert und anschließend in Form von Schlüsselwörtern charakterisiert werden. Aufgrund seiner Verbreitung wurde das LDA-Verfahren im Projekt als „Baseline“ implementiert, die es von anderen Verfahren zu schlagen gilt. Das LDA-Verfahren wurde in den letzten Jahren stetig weiterentwickelt und bereits auf eine Vielzahl von Anwendungen optimiert. Aufgrund fehlender freizugänglicher Implementierungen, fanden jedoch zahlreiche dieser Verbesserungen und Erweiterungen im industriellen Kontext bisher kaum Beachtung. Das „InfoFormulizer“ Projekt schließt in dieser Hinsicht also eine entscheidende Lücke.
Für den „InfoFormulizer“ wurden drei LDA basierte Ansätze ausgewählt: (i) das Correlated Topic Model (CTM), die Gaussian Latent Dirichlet Allocation (GLDA) und der Hierarchical Dirichlet Process (HDP). Diese Erweiterungen von LDA bieten mehrere Vorteile, die deren Nutzung angesichts der Anforderungen im Projekt attraktiv machen. Beispielsweise ist es mit HDP möglich die Anzahl an Themenkomplexen innerhalb einer Dokumentensammlung automatisch zu bestimmen, während beim „klassischen“ LDA die Anzahl der Themen vorab bekannt sein muss oder dieser man sich in aufwendigen Versuchen der (optimalen) Themenzahl annähern muss.
Eine zentrale Herausforderung bestand darin zu evaluieren, wie gut die verschiedenen LDA-Verfahren funktionieren, d.h. inwiefern es ihnen entweder gelingt alle bekannten Themen und / oder möglichst passende Themen zu finden. Das Problem der Themenidentifikation ist Gegenstand zahlreicher Forschungsarbeiten, jedoch sind bisher nur eine überschaubare Anzahl an Metriken entwickelt worden. Da die Anwendungspartner aus unterschiedlichen Domänen stammen bestand die zusätzliche Anforderung, dass die verwendeten Metriken nicht auf eine einzelne Domäne zugeschnitten sein dürfen, sondern eine domänenübergreifende Aussagekraft besitzen müssen. Die durchgeführte Literaturrecherche ergab hierbei die sog. „Topic Coherence“, die in verschiedenen Studien eine starke Übereinstimmung zwischen menschlicher Wahrnehmung von Themen und berechneter Güte aufwies. Allerdings hat die Topic Coherence den Nachteil, dass deren Berechnung insbesondere für (sehr) große Datensätze sehr rechenintensiv ist. Grund hierfür ist, dass für die Berechnung eine Matrix (sog. Interval Co-Occurrence Matrix) aufgebaut wird, die quadratisch mit der Größe des Vokabulars (bzw. der Token) des zu verarbeitenden Textes anwächst. So erhält man etwa für den ACL-Datensatz eine 190.000 x 190.000 Matrix, die sich nur durch massive Optimierungen in der Berechnung auswerten lies (insbesondere Parallelisierung, Zerlegung in Teilmatrizen, etc.).
Als zweite zentrale Metrik wurde die „Perplexity“ ausgewählt. Die zeigt an, wie gut ein Topic Modell in der Lage ist, neue, ungesehene Texte zu modellieren. Ein niedriger Perplexitätswert deutet darauf hin, dass das Modell bessere Vorhersagen über die Verteilung der Wörter in den Dokumenten macht und somit besser geeignet ist, um Themen zu identifizieren. Folglich ist also eine niedrige Perplexity wünschenswert. Bei der Interpretation der Perplexity muss jedoch beachtet werden, dass diese nur ein Maß für die Vorhersagekraft eines Topic-Modells ist und nicht unbedingt ein Indikator für die Qualität der zugrunde liegenden Themen oder die Interpretierbarkeit des Topic-Modells. Es kann also passieren, dass ein Topic-Modell eine niedrige Perplexity aufweist, aber trotzdem schlecht interpretierbare Themen produziert.
Da mittels des InfoFormulizers letztendlich Dokumente gefunden werden sollen, die Antworten auf Supportanfragen enthalten, muss zusätzlich noch gemessen werden, wie gut Verfahren ebendiese Dokumente identifizieren können. Hierfür wurde im Projekt der sog. Mean -Rank (MR) verwendet. Bei dieser Metrik werden zunächst alle Dokumente absteigend nach deren Passung geranked (d.h. an erster Stelle in der Liste steht das Dokument, das vom Algorithmus als am passendsten angesehen wird). Die Passung von Frage und Dokument wird über die Kosinusdistanz berechnet. Hierzu wird die Kosninusdistanz zwischen Fragevektor und Dokumentenvektor berechnet. Die Kosinusdistanz berechnet den Winkel zwischen den beiden Vektoren. Die Idee dahinter, ist dass wenn die beiden Vektoren sich sehr ähnlich sind, diese sich auch in einem ähnlichen Winkel befinden. Veranschaulichen lässt sich dies sehr gut im zweidimensionalen Raum. Vektoren, die sich sehr ähnlich sind, zeigen die gleiche Richtung (Winkel zwischen den Vektoren klein). Zeigen diese in entgegengesetzte Richtung sind diese maximal unterschiedlich (Winkel sehr groß, nämlich 180 Grad). Die Kosinusdistanz gilt in der NLP-Forschung als effektive Methode zur Berechnung von Vektorähnlichkeiten. Aus dieser Liste von Kosinusähnlichkeiten wird dann der Rank des korrekten Dokuments ermittelt. Dieses Verfahren wird für alle Fragen wiederholt und abschließend der Mittelwert über alle Ranks gebildet. Diese Metrik hat den Vorteil, dass sie eine für die Problemstellung sehr anschauliche Interpretation besitzt. In der Praxis würde ein Supportmitarbeiter / eine Supportmitarbeiterin zum Beantworten der Supportanfrage zunächst auf das vom Algorithmus am wahrscheinlichsten angesehen Dokument zurückgreifen. Wenn dies nicht passend ist, schließlich auf das zweitwahrscheinlichste zurückgreifen, danach ggf. auf das drittwahrscheinlichste und so weiter, bis das passende Dokument erhalten wurde. Der MR gibt nun an, wie viele vom Algorithmus vorgeschlagene Dokumente ein Supportmitarbeiter / eine Supportmitarbeiterin durchschnittlich durchsehen müsste, bis er / sie das korrekte Dokument erhalten hat. Dementsprechend ist ein besonders kleiner MR-Wert zu bevorzugen, da dieser anzeigt, dass das richtige Dokument weit oben geranked wird. Aus praktischer Sicht ist diese Metrik am wichtigsten, da sich hiermit der tatsächliche praktische Nutzen und die damit verbundene Zeit- und Kosteneinsparung beurteilen lässt. Andere Metriken wie die Genauigkeit (sog. Accuracy), die nur messen würden in wie vielen Fällen direkt das richtige Dokument vorgeschlagen wurde, würden dagegen ein unvollständiges oder gar irreführendes Bild zeichnen. So würde beispielsweise ein Algorithmus, der in der Hälfte der Fälle direkt das richtige Dokument vorschlägt und ansonsten dieses auf den letzten Rank einsortiert, besser abschneiden als ein Algorithmus, der nur in 30% der Fälle direkt das richtige Dokument findet, aber ansonsten das richtige Dokument zumindest auf die Plätze zwei und drei setzt. Aus praktischer Sicht wäre aber definitiv der zweite Algorithmus zu bevorzugen.
- Übersicht der ErgebnisseHide
-
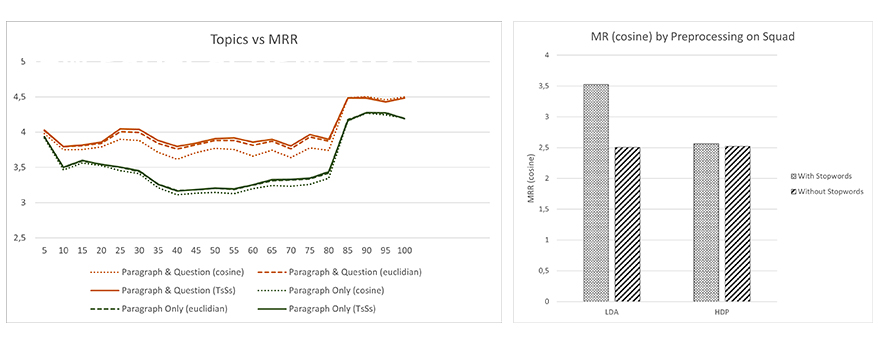
Unsere Experimente zeigen, dass HDP das LDA-Verfahren von der Leistungsfähigkeit zumindest auf dem SQuAD Datensatz klar übertrifft (siehe Tabelle). Die besten Ergebnisse konnten bei LDA mit einer Themenanzahl von k=20 und k=40 erzielt werden. Für die beiden Datensätze der Unternehmenspartner ergibt sich ein etwas differenzierteres Bild. So erzielt LDA auf dem Datensatz der New Ventures GmbH ein leicht besseres Ergebnis als HDP (1.48 vs. 1.85). Im Fall des Datensatzes der Samhammer AG dagegen ist ein zu SQuAD ähnliches Verhalten zu beobachten. Hier schneidet HDP deutlich besser als die beiden LDA-Varianten ab. In allen Fällen, d. h. sowohl auf SQuAD, als auch den Datensätzen der Praxispartner, zeigt sich die Überlegenheit der Topic Modell basierten Lösung gegenüber reinen Embedding Techniken wie Doc2Vec oder dem kombinierten Verfahren aus Doc2Vec und Clustering (siehe Tabelle). Mittels der Stoppwörterentfernung konnte auf allen Datensätzen eine Verbesserung erzielt werden. Die im Fall des New Ventures Datensatz durchgeführte weitere Optimierung mit der Entfernung von domänspezifischen Stoppwörtern führte nochmals zu einem kleinen Performancegewinn (siehe Abbildung 3) im Fall des am besten funktionierenden Modells (LDA mit 20 Themen). Das zuvor etwas schlechter abschneidende Verfahren HDP konnte dagegen von der Stoppwortentfernung nicht profitieren und erlitt einen Leistungseinbruch. Hier handelt es sich allerdings um eine Anomalie, welche für den Datensatz des Partners New Ventures spezifisch ist, da sich für beide anderen Datensätze ein positiver Effekt beobachten ließ. Wie die untenstehende Abbildung zeigt, liegt diese Anomalie allerdings nicht an der domänenspezifischen Stoppwortliste, sondern am Datensatz im Allgemeinen, da unter Verwendung des Datensatzes SQuAD HDP keine Leistungseinbußen verzeichnet, sondern von Stoppwortentfernung profitiert, wenn auch nur marginal.
SQuAD
New Ventures Datensatz
Samhammer AG Datensatz
LDA (k=20)
3.53
1.48
4.80
LDA (k=40)
3.11
1.54
5.10
HDP
2.56
1.85
3.48
LDA (k=20) + Stoppwortentfernung
2.51
1.40
4.98
HDP + Stoppwortentfernung
2.52
2.92
3.27